
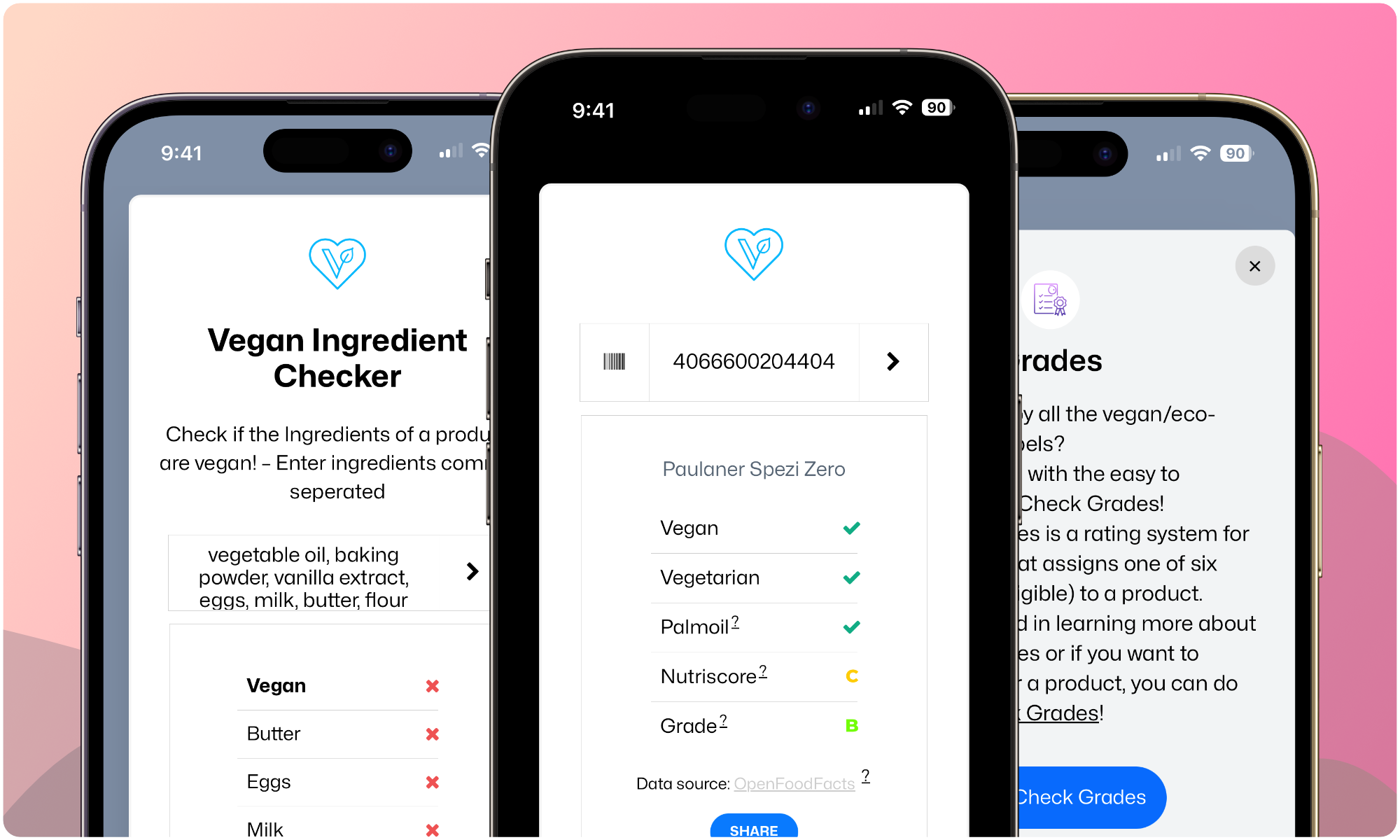









Veganify checks the barcode (EAN or UPC) of a food- or non-food-product and tells you if it is vegan or not. It is an useful tool for vegans and vegetarians – Developed with usability and simplicity in mind, so without distracting irrelevant facts or advertising. Veganify combines the Databases of OpenFoodFacts, OpenBeautyFacts and Open EAN Database, as well as our very own ingredient checker in one tool.
See an example of how it works!
The Veganify Ingredients API checks the products ingredients against a list of thousands of non-vegan items.
Open PWA in browser | Product page on FrontEndNetwork | Use the API | iOS Shortcut | Uptime Status
Tip
We’re using Conventional Commits for commit messages. Please follow this convention when making changes.
- Node.js 20 or later
- pnpm (enabled via corepack)
To enable pnpm using corepack:
corepack enable
corepack prepare pnpm@latest --activate-
Clone the repository:
git clone https://github.com/frontendnetwork/veganify.git cd veganify -
Install dependencies & start dev server:
pnpm install pnpm dev
src/
├── @components/
│ ├── shared/
│ ├── ComponentName/
│ │ ├── hooks/ # Component-specific hooks
│ │ ├── utils/ # Component-specific utilities
│ │ │ ├── util.ts
│ │ │ └── util.test.ts # Utility specify tests
│ │ ├── models/ # Component-specific types/interfaces
│ │ ├── componentPart.tsx # Component files
│ │ └── index.tsx # Component files
├── @models/ # Global type definitions
├── styles/ # CSS styles
├── tests/ # Only test setup files & Playwright tests
└── locales/ # next-intl translation files
# Start development server
pnpm dev
# Run linting
pnpm lint
# Run type checking
pnpm check-types
# Run unit tests
pnpm test
# Run end-to-end tests
pnpm test:e2e
# Build for production
pnpm buildNote
We’re aware not everything in this repo follows those standards. This is because of how the project was started and evolved. We’re working on improving this.
- Break down components into smaller, reusable pieces
- Each significant component should have its own directory with the following structure:
hooks/for component-specific hooksutils/for component-specific utilitiesmodels/for component-specific types
- Small, simple components can be single files
- All utility functions must have 100% test coverage
- Tests are written using Jest for unit testing
- Components currently don’t require test coverage
- Playwright is used for end-to-end testing but currently only coversa few basics use cases. More tests are needed.
- TypeScript is mandatory
- The
anytype is not acceptable unless absolutely necessary - Always define proper interfaces and types in the appropriate
modelsfolder - Use type inference when possible
- Use
next-intlfor translations - Add new translations to all language files in
/locales - Follow the existing translation key structure
- Follow Node.js, React, and Next.js best practices
- Use the App Router pattern for routing
- Keep components pure and functional when possible
- Use hooks for state management and side effects
- Follow the DRY (Don’t Repeat Yourself) principle
- Use meaningful variable and function names
- Write comments for complex logic
- Keep functions small and focused
- Place all styles in the
stylesfolder - Keep styles modular and scoped to components when possible
- Be sure to use SCSS for styling
- Use CSS variables for theming and repeated values
When making a contribution, please follow these guidelines to ensure consistency and maintainability.
Remember that every contribution, no matter how small, is valuable to the project. Thank you for helping make Veganify better!
Please refer to our issue trackers to see where you could help:
or if you find something else you could improve, just open a new issue for it!






This repo uses:
All text and code in this repository is licensed under MIT, © 2024 Philip Brembeck, © 2024 FrontEndNetwork.
 https://github.com/frontendnetwork/veganify
https://github.com/frontendnetwork/veganify














































{kind=link}